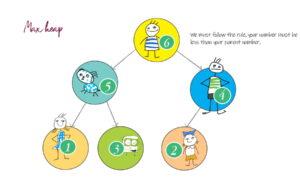
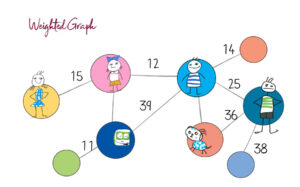
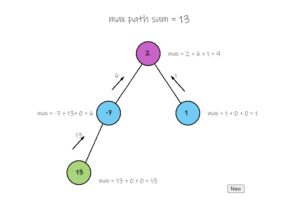
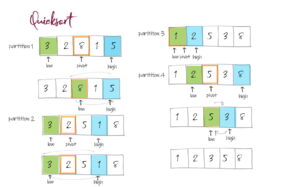
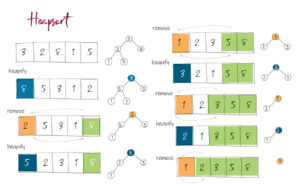
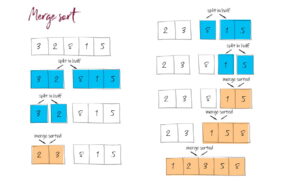
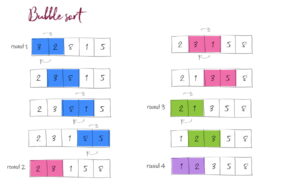
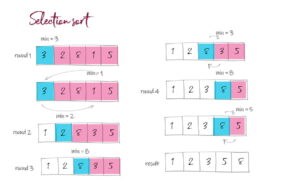
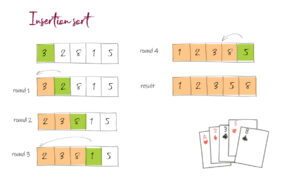
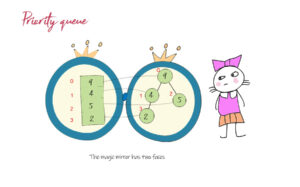
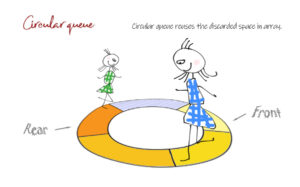
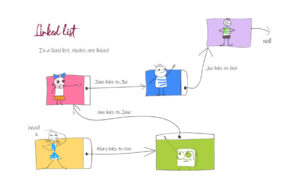
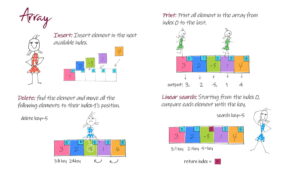
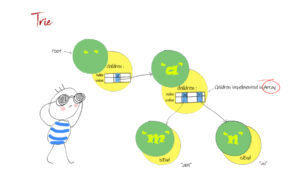
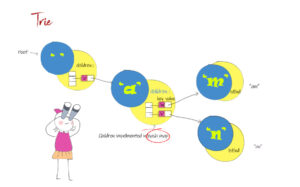
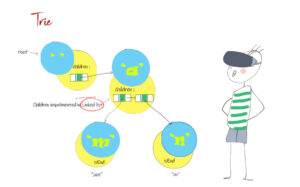
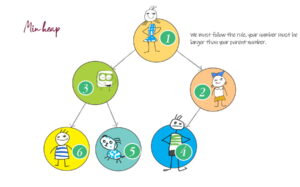
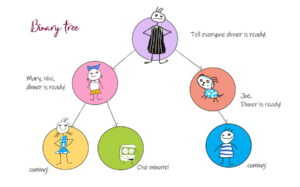
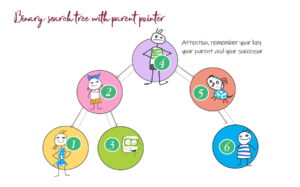
Coding for BeginnersData Structures and AlgorithmsGrokking Data StructuresAlgorithmsMax heap implementationWeighted graph as adjacency listMax path sum – generative artQuick sort gif | Code and visualsHeapsort gif – how heapify worksMerge sort gif | code and visualsBubble sort gifSelection sort gif | code and visualsInsertion sort gif | code and visualsData structuresPriority queue implementation using a heap – iterative solutionCircular queue implementation using an arrayPriority queue implementation using an ordered array – Priority queue 2Hash table implementationPriority queue implementation using a heap – recursive solutionImplement a stack class using an arrayImplement a linked list classImplement an array classPriority queue implementation using an unordered array – Priority queue 1 TreesTrie implementation using an arrayTrie map – trie implementation using a hashmapTrie list – trie implementation using a linked listMin heap implementationMax heap implementationBinary tree implementationBinary search tree with parent pointerBinary search tree implementation GraphsImplement an adjacency list graphWeighted graph as adjacency list