A hash table is a data structure that maps keys to values for fast access. From the key, the correct value can be stored and found. The time complexity is close to constant O(1). The hash table is one of the most used data structures. This post has a hash table implementation in Java, JavaScript, and Python.
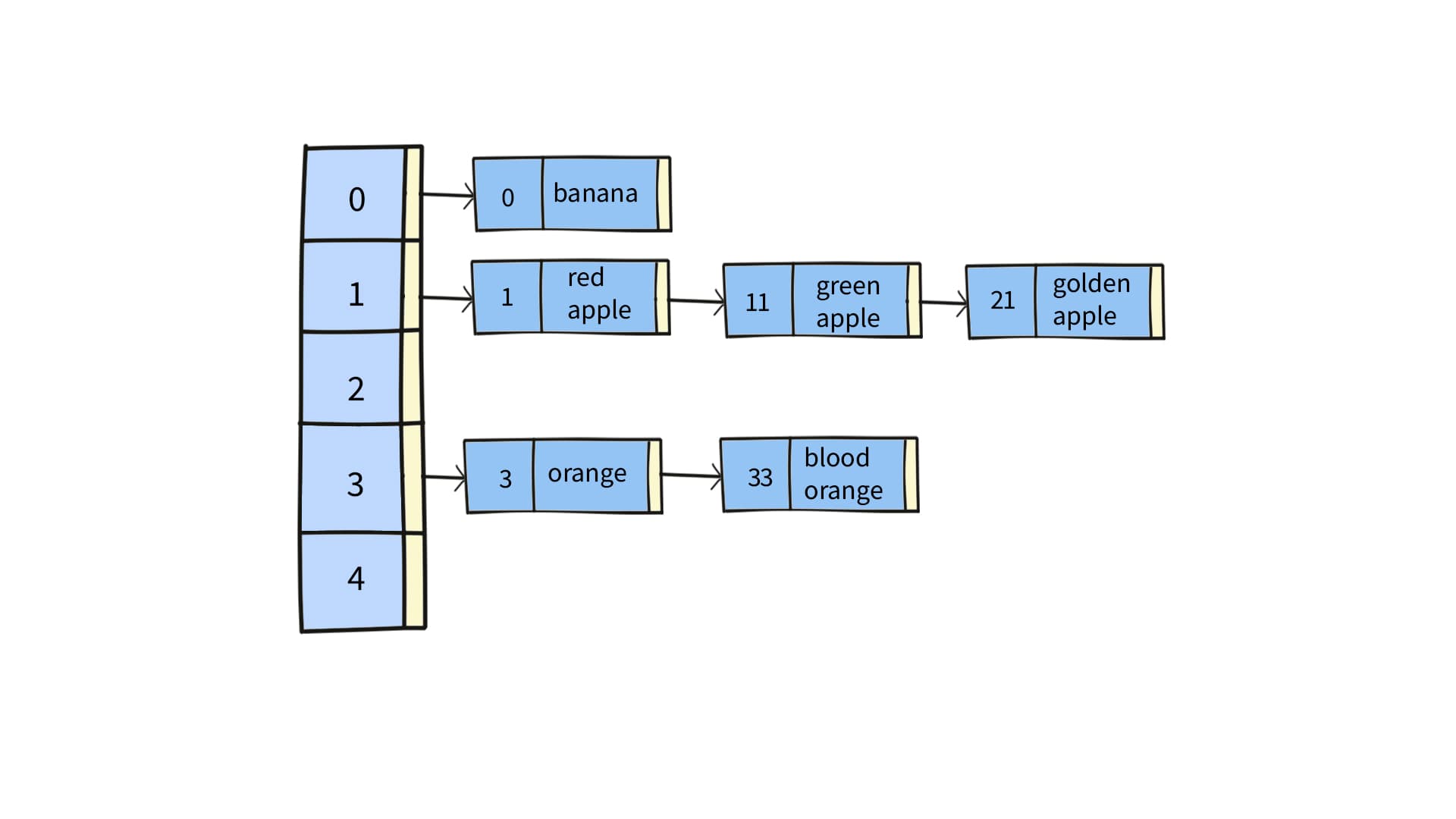
Table of Content
Define classes
The first thing is to define the Entry class, which is a key-value pair. It has two attributes, key and value. Their data type can be anything such as Integer, String, or a customer-defined class.
After defining the Entry class, we can define a HashTable class. The HashTable has two attributes, buckets and maxSize. buckets is an array of entries. However, two keys may generate an identical hash value, which causes both keys to point to the same bucket. Multiple entries coming to the same bucket form a list. So buckets is an array of lists of entries. maxSize is the initial length of buckets.
Java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | import java.util.LinkedList; class Entry<K, V> { K key; V value; //Constructor, Time O(1), Space O(1) public Entry(K key, V val) { this.key = key; this.value = val; } //Check equality of entry,compare value not object, Time O(1), Space O(1) public boolean equals(Entry<K, V> entry) { if (!this.key.equals(entry.key)) return false; return this.value.equals(entry.value); } //Override, Time O(1), Space O(1) @Override public String toString() { return "(" + key.toString() + ", " + value.toString() + ")"; } } public class HashTable<K, V> { private int maxSize; private LinkedList<Entry<K, V>>[] buckets; //Constructor, Time O(1), Space O(m), m is max size @SuppressWarnings("unchecked") public HashTable(int capacity) { maxSize = capacity; buckets = ((LinkedList<Entry<K, V>>[]) new LinkedList[maxSize]); } |
Javascript
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | class Entry { //Constructor, Time O(1), Space O(1) constructor(key, val) { this.key = key; this.value = val; } //Check equality of entry, compare value not object, Time O(1), Space O(1) equals(entry) { if ( this.key != entry.key) return false; return this.value == entry.value; } //Override, Time O(1), Space O(1) toString() { return "(" + this.key.toString() + ", " + this.value.toString() + ")"; } } class HashTable { //Constructor, Time O(1), Space O(1) constructor(capacity) { this.maxSize = capacity; this.buckets = new Array(this.maxSize); } |
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | class Entry: #Constructor, Time O(1), Space O(1) def __init__(self, key, val): self.key = key self.value = val #Check equality of entry, compare value not object, Time O(1), Space O(1) def equals(self, entry): if str(self.key) != str(entry.key): return False return str(self.value) == str(entry.value) #Override, Time O(1), Space O(1) def __str__(self): return "(" + str(self.key) + ", " + str(self.value) + ")" class HashTable: #Constructor, Time O(1), Space O(1) def __init__(self,capacity): self.maxSize = capacity self.buckets = [None]*(self.maxSize) |
Hashing and hash function
Hashing is a technique to map a range of keys to a range of indices of the buckets. If both ranges are similar, no hash function is necessary. The key values can be used directly as array indices.
But more often the range of the indices is much smaller than the range of the keys. The hash function hashes(converts) a number in a large range into a number in a smaller range. Using the modulo operator(%) is an easy and common hash function. The formula is:
hashCode = key % maxSize.
hashCode is the index of buckets. key in the key of the input entry. maxSize is the max length of buckets. To distribute hashCode more evenly over the array, maxSize is suggested to be a prime number.
Java
1 2 3 4 | //Calculate hashcode by key, Time O(1), Space O(1) public int hashFunc(K key) { return Integer.parseInt(key.toString()) % maxSize; } |
JavaScript
1 2 3 4 | //Calculate hashcode by key, Time O(1), Space O(1) hashFunc(key) { return key % this.maxSize; } |
Python
1 2 3 | #Calculate hashcode by key, Time O(1), Space O(1) def hashFunc(self, key): return int(key) % self.maxSize |
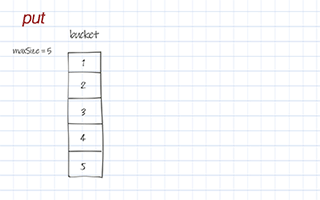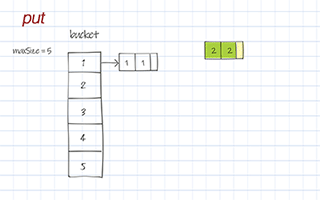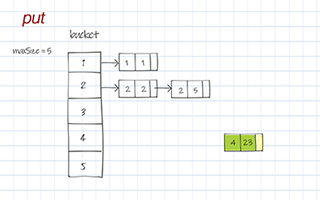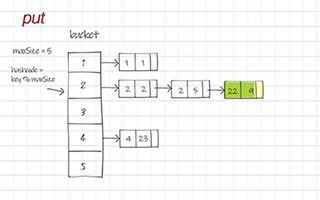
The put method in hash table implementation
The put operation saves a (key, value) entry to buckets. First, it calls hashFunc() to get the hashCode, i.e. the index to access the right bucket. If the bucket’s list is null, create a new list. Then add the new entry of the given (key, value) pair to the list.
Java
1 2 3 4 5 6 7 8 9 10 11 12 13 | //Add an entry, Time O(1), Space O(1) public void put(K key, V value) { int x = hashFunc(key); if (x < 0) { System.out.println("invalid hash code"); return; } if (buckets[x] == null) buckets[x] = new LinkedList<Entry<K, V>>(); LinkedList<Entry<K, V>> list = buckets[x]; Entry<K, V> entry = new Entry<K, V>(key, value); list.add(entry); } |
JavaScript
1 2 3 4 5 6 7 8 9 10 11 | //Add an entry, Time O(1), Space O(1) put(key, value) { var x = this.hashFunc(key); if (x < 0) return; if (this.buckets[x] == null) this.buckets[x] = new Array(); var list = this.buckets[x]; var entry = new Entry(key, value); list.push(entry); } |
Python
1 2 3 4 5 6 7 8 9 10 | #Add an entry, Time O(1), Space O(1) def put(self, key, value): x = self.hashFunc(key) if x < 0: return if self.buckets[x] == None: self.buckets[x] = [] list = self.buckets[x] entry = Entry(key, value) list.append(entry) |
Doodle
Delete
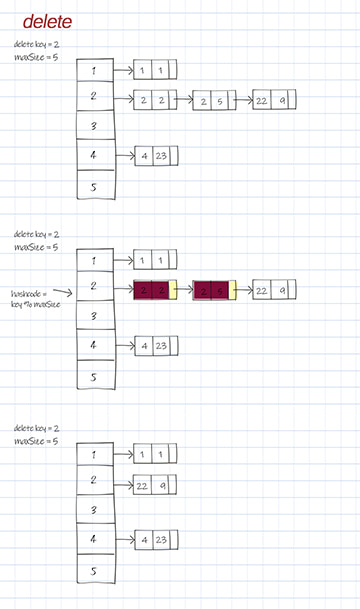
Delete by key is to delete all entries with that key. The first thing is to call hashFunc to get the hashCode to access the right bucket. Then compare the key with each entry’s key in the list. To be thread-safe, a new list is created to back up the entries whose key is not the same as the input key. If all entries in the list are deleted, set the list in this bucket to null. Otherwise, reset the list of this bucket to the new list.
Java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | //Delete all entries by key, Time O(n), Space O(n), n is max length of list in bucket public void delete(K key) { int x = hashFunc(key); if (x < 0) { System.out.println("invalid hash code"); return; } if (buckets[x] == null) return; LinkedList<Entry<K, V>> list = buckets[x]; LinkedList<Entry<K, V>> newList = new LinkedList<>(); //copy to another list for (Entry<K, V> entry : list) { if (!entry.key.equals(key)) { newList.add(entry); } } buckets[x] = (newList.size() == 0) ? null: new LinkedList<>(newList); } |
JavaScript
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | //Delete all entries by key, Time O(n), Space O(n), n is max length of list in bucket delete(key) { var x = this.hashFunc(key); if (x < 0) return; if (this.buckets[x] == null) return; var list = this.buckets[x]; var newList = new Array(); for (let entry of list) { if (entry.key !== key) newList.push(entry); } this.buckets[x] = (newList.length == 0)? null: new Array(newList); } |
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 | #Delete all entries by key, Time O(n), Space O(n), n is max length of list in bucket def delete(self, key): x = self.hashFunc(key) if x < 0: return if self.buckets[x] == None: return list = self.buckets[x] newList = [] for entry in list: if str(entry.key) != str(key): newList.append(entry) self.buckets[x] = None if len(newList) == 0 else newList |
Doodle
Get
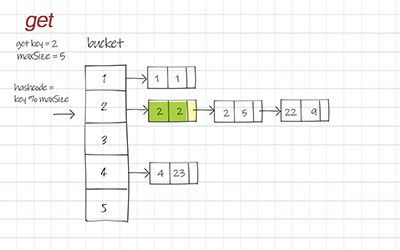
The get operation is to get the value by the key. Call hashFunc() to get the hashCode to access the right bucket. Then compare the key with each entry’s key in the list. Return the first matched entry’s value.
If there is only one item in the list, the time complexity is O(1). If there are many items in the list, access time is O(n) in the worst scenario. n is the length of this list.
Java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | //Return first found value by key, Time O(n), Space O(1), n is max length of list in bucket public V get(K key) { int x = hashFunc(key); if (x < 0) { System.out.println("invalid hash code"); return null; } if (buckets[x] == null) return null; LinkedList<Entry<K, V>> list = buckets[x]; for (Entry<K, V> entry : list) { if (entry.key.equals(key)) return entry.value; } return null; } |
JavaScript
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | //Return first found value by key, Time O(n), Space O(1), n is max length of list in bucket get(key) { var x = this.hashFunc(key); if (x < 0) return null; if (this.buckets[x] == null) return null; var list = this.buckets[x]; for (let entry of list) { if (entry.key == key) return entry.value; } return null; } |
Python
1 2 3 4 5 6 7 8 9 10 11 12 | #Return value by key, Time O(n), Space O(1), n is max length of list in bucket def get(self, key): x = self.hashFunc(key) if x < 0: return None if self.buckets[x] == None: return None list = self.buckets[x] for entry in list: if str(entry.key) == str(key): return entry.value return None |
Doodle
Print
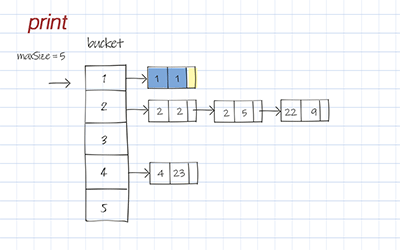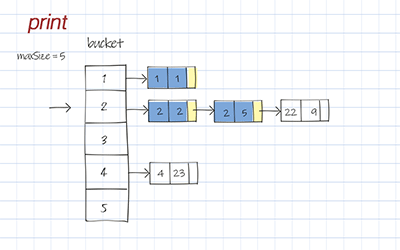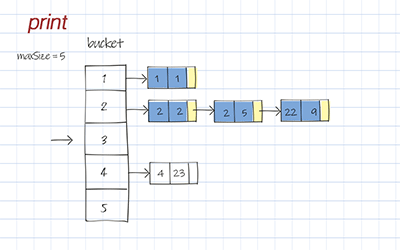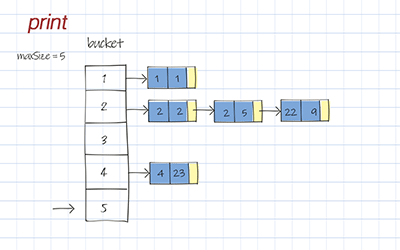
Print is to print all entries in the Hash table. It loops through each bucket and prints elements in the list. If the list is empty, skip it.
Java
1 2 3 4 5 6 7 8 9 10 11 12 | //Print the whole hash table, Time O(m+n), Space O(1), //m is the size of the buckets, n is number of entries in a hashtable void print() { for (int i = 0; i < maxSize; i++) { LinkedList<Entry<K, V>> list = buckets[i]; if (list != null) { for (Entry<K, V> entry : list) System.out.print(entry + " "); System.out.println(); } } } |
JavaScript
1 2 3 4 5 6 7 8 9 10 11 12 13 | //Print the whole hash table, Time O(m+n), Space O(n), //m is the size of the buckets, n is number of entries in a hashtable print() { for (let i = 0; i < this.maxSize; i++) { let list = this.buckets[i]; if (list != null) { var s = ''; for (let entry of list) s += entry + ' ' ; console.log(s); } } } |
Python
1 2 3 4 5 6 7 8 9 | #Print the whole hash table, Time O(m+n), Space O(1), #m is the size of the buckets, n is number of entries in a hashtable def print(self): for i in range(0, self.maxSize): list = self.buckets[i] if list != None: for entry in list: print(str(entry) , end = " ") print() |
Doodle
Free download
Download hash table implementation in Java, JavaScript and Python
Illustrated Data Structures (Java) Book